代理模型
本文最后更新于:2023年1月19日 下午
代理模型简介
代理模型是复杂工程优化设计问题的关键技术之一。许多复杂问题的优化方法,如遗传算法、模拟退火算法、粒子群算法和蚁群算法等等。与传统的基于梯度的优化方法比,上述这些算法具有很好的鲁棒性、全局性和高度并行性等特点,在多峰值的非线性函数优化问题中得到了成功的应用。但是这些算法的最大缺点是收敛速度慢,需要对目标函数进行大量的评估,如果目标函数评估方法比较耗时(如工程优化中的CFD和FEM分析),则计算量很大,严重制约了其在工程中的应用。为了克服全局优化算法的这个缺点,人们采用了一种称为代理模型(surrogate model)的方法来代替耗时的精确模型评估。代理模型的计算量比精确模型小得多,同时精度也可以得到保证,采用代理模型可以大大减少优化过程的计算量,提高工程优化设计的效率。常用的代理模型主要包括插值法、响应面模型、人工神经元网络模型、径向基函数模型及Kriging模型等。其中Kriging模型具有训练样本点处无偏估计、良好的高度非线性近似能力,非常适合作为代理模型使用。目前Kriging模型在工程优化设计领域得到了广泛应用。[1]
这其中,多项式响应面、多项式插值接近于回归拟合领域,比较简单。相对于分类支持向量机,支持向量机回归其应用较少,在此不做讨论。神经网络作为一套独立的体系,应该说其对原模型的近似程度最高,随着节点和隐含层的增多,实现模型的完美逼近。不过其运算速度也不会很快,且可解释性差,很多网络本身就是一个黑箱。克里金插值和径向基函数插值是目前应用较多的两种方法。
1. 插值法
利用函数f (x)在某区间中插入若干点的函数值,作出适当的特定函数,在这些点上取已知值,在区间的其他点上用这特定函数的值作为函数f (x)的近似值。
2. 响应面模型
也称作响应曲面设计方法(Response Surface Methodology,RSM),是通过一系列多变量试验,通过多项式回归方程来模拟真实状态曲面的方法。一般情况下,二次回归方程可以给出较为满意的答案,即 \[ \begin{equation} y=\beta_{0}+\sum_{i=1}^{m} \beta_{i} x_{i}+\sum_{i=1}^{m} \beta_{i i} x_{i} x_{i}+\sum \sum_{i<j} \beta_{i j} x_{i} x_{j}+\varepsilon \end{equation} \] 写成更紧凑的形式: \[ \begin{equation} y_{i}=\beta_{0}+\sum_{j=1}^{k} \beta_{j} x_{i j}+\varepsilon_{i} \quad i=1,2, \ldots, n \end{equation} \] 多次观测后写成矩阵形式为: \[ \begin{equation} \mathbf{y}=\mathbf{X} \boldsymbol{\beta}+\boldsymbol{\varepsilon} \end{equation} \] 其中 \[ \begin{equation} \begin{split} & \mathbf{y}=\left[\begin{array}{c} y_{1} \\ y_{2} \\ \vdots \\ y_{n} \end{array}\right], \mathbf{X}=\left[\begin{array}{ccccc} 1 & x_{11} & x_{12} & \ldots & x_{1 k} \\ 1 & x_{21} & x_{22} & \ldots & x_{2 k} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ 1 & x_{n 1} & x_{n 2} & \ldots & x_{n k} \end{array}\right], \\ & \boldsymbol{\beta}=\left[\begin{array}{c} \beta_{0} \\ \beta_{1} \\ \vdots \\ \beta_{k} \end{array}\right],\boldsymbol{\varepsilon}=\left[\begin{array}{c} \varepsilon_{0} \\ \varepsilon_{1} \\ \vdots \\ \varepsilon_{k} \end{array}\right] \end{split} \end{equation} \]
观测误差方差为 \[ \mathbf{L}=\sum_{i=1}^{n} \varepsilon_{i}^{2}=\boldsymbol{\varepsilon}^{\prime} \boldsymbol{\varepsilon}=(\mathbf{y}-\mathbf{X} \boldsymbol{\beta})^{\prime}(\mathbf{y}-\mathbf{X} \boldsymbol{\beta}) \] 当方差最小时,显然拟合曲面和实际值最接近,此时 \[ \left.\frac{\partial \mathbf{L}}{\partial \boldsymbol{\beta}}\right|_{\hat{\beta}}=-2 \mathbf{X}^{\prime} \mathbf{y}+2 \mathbf{X}^{\prime} \mathbf{X} \hat{\boldsymbol{\beta}}=0 \]
则
\[ \hat{\boldsymbol{\beta}}=\left(\mathbf{X}^{\prime} \mathbf{X}\right)^{-1} \mathbf{X}^{\prime} \mathbf{y} \]
可得响应面为
\[ \hat{\mathbf{y}}=\mathbf{X} \hat{\boldsymbol{\beta}} \]
3. 神经网络模型
一种万能逼近模型。当代人工智能、深度学习的核心。
4. 径向基函数模型
1985年,Powell提出了多变量插值的径向基函数(RBF)方法。1988年Moody和Darken提出了一种神经网络结构,即RBF神经网络,属于前向神经网络类型,它能够以任意精度逼近任意连续函数,特别适合于解决分类问题。
RBF网络的结构与多层前向网络类似,它是一种三层前向网络。输入层由信号源结点组成,第二层为隐含层,隐单元数视所描述问题的需要而定,隐单元的变换函数是RBF,它是对中心点径向对称且衰减的非负非线性函数,第三层为输出层,它对输入模式的作用作出相应。从输入空间到隐含层空间的变换是非线性的,而从隐含层空间到输出层空间变换是线性的。
RBF网络的基本思想是:用RBF作为隐单元的“基”构成隐含层空间,这样就可以将输入矢量直接映射到隐空间,而不需要通过权连接。当RBF的中心点确定以后,这种映射关系也就确定了。而隐含层空间到输出空间的映射是线性的,即网络的输出是隐单元输出的线性加权和,此处的权即为网络可调参数。从总体上看,网络由输入到输出的映射是非线性的,而网络输出对可调参数而言却又是线性的。这样,网络由输入到输出的映射是非线性的,而网络输出对可调参数而言却又是线性的。这样网络的权就可由线性方程组直接解出,从而大大加快学习速度并避免局部极小问题。
5. 克里金模型
克里金(Kriging)模型实际上就是高斯随机过程模型,只是实现上稍有不同。
代理模型在优化过程中的使用方式非常重要,最常用的也是最简单的方式是以代理模型的预测值为目标函数对其寻优得到校正点,然后把校正点用精确模型评估并把结果用以更新代理模型,依此往复迭代直至收敛。这种选择校正点的方法极易使优化过程陷入局部极值点。Kriging模型与多项式响应面模型及人工神经网络模型最大的不同之处在于,Kriging模型不仅提供了1) 未知点处的预测值,还提供了2) 未知点处的预测标准差,可以方便地衡量预测的精度。针对简单地对代理模型预测值寻优确定校正点的方法所带来的局部收敛问题。Schonlau提出了以 Kriging 模型为代理模型的 EGO(efficient global optimization)算法, 该算法在 选取校正点时综合考虑了 Kriging 模型的预测值和 预测精度 ,避免了优化过程局部收敛的风险。
5.1 克里金模型的基本理论
形式一 [6]
\[ \left\{\begin{array}{l} \hat{y}_{1}(x)=\hat{\mu}+r^{T} C^{-1}(y-\mathbf{1} \hat{\mu}) \\ s_{1}^{2}(x)=\hat{\sigma}\left[1-r^{T} C^{-1} r+\frac{\left(1-\mathbf{1}^{T} C^{-1} r\right)^{2}}{\mathbf{1}^{T} C^{-1} \mathbf{1}}\right] \end{array}\right. \]
其中 \[ \left\{\begin{array}{l} \hat{\mu}=\frac{\mathbf{1}^{T} C^{-1} y}{\mathbf{1}^{T} C^{-1} \mathbf{1}} \\ \hat{\sigma}^{2}=\frac{(y-\mathbf{1} \hat{\mu})^{T} C^{-1}(y-\mathbf{1} \hat{\mu})}{n} \end{array}\right. \] 假设有n个数据点,1个预测点。r是数据点X和预测点x之间的协方差矩阵。C是数据点X之间的协方差矩阵。y是数据点的目标值。1是n*1的矩阵。
形式二 [7]
\[ \left\{\begin{array}{l} \hat{y}_{2}(x)=f(x)^{T} \beta^{*}+r^{T}(x) \gamma^{*} \\ s_{2}^{2}(x)=\sigma^{2}\left(1+u^{T}\left(F^{T} C^{-1} F\right)^{-1} u-r^{T} R^{-1} r\right) \end{array}\right. \]
其中 \[ \left\{\begin{array}{l} \beta^{*}=\left(F^{T} R^{-1} F\right)^{-1} F^{T} C^{-1} Y \\ C \gamma^{*}=Y-F \beta^{*} \\ u=F^{T} C^{-1} r-f(x) \\ \sigma^{2}=\frac{1}{m}\left(Y-F \beta^{*}\right)^{T} C^{-1}\left(Y-F \beta^{*}\right) \end{array}\right. \] 形式一是形式二在基函数为0次函数(即f(x)=1)时的特例。
对于形式一,给定数据集为\(\boldsymbol{X}=\{\boldsymbol{x}^{1}, \boldsymbol{x}^{2}, \ldots, \boldsymbol{x}^{n}\}^{T}\),对应的目标函数为\(\boldsymbol{y}=\{y^{1}, y^{2}, \ldots, y^{n}\}^{T}\)克里金法假设所有数据之间都服从n维的正态分布。所以目标函数\(\boldsymbol{y}\)是一个随机过程,里面的每一个变量\(y_i\)都是一个随机变量。我们把这个随机过程记做: \[ \left(\begin{array}{c} Y\left(\boldsymbol{x}^{\mathbf{1}}\right) \\ Y\left(\boldsymbol{x}^{\mathbf{1}}\right) \\ \vdots \\ Y\left(\boldsymbol{x}^{n}\right) \end{array}\right) \sim N(\boldsymbol{\mu}, C) \] 我们把均值取为常数\(\boldsymbol{1}\) 是n*1的矩阵。协方差取为 \[ \begin{equation} \begin{aligned} &\operatorname{cor}\left[Y\left(\boldsymbol{x}^{i}\right), Y\left(\boldsymbol{x}^{l}\right)\right]=\exp \left(-\sum_{j=1}^{k} \theta_{j}\left|x_{j}^{i}-x_{j}^{l}\right|^{2}\right) \\ &C=\left(\begin{array}{ccc} \operatorname{cor}\left(Y\left(\boldsymbol{x}^{\mathbf{1}}\right), Y\left(\boldsymbol{x}^{\mathbf{1}}\right)\right), & \ldots, & \operatorname{cor}\left(Y\left(\boldsymbol{x}^{\mathbf{1}}\right), Y\left(\boldsymbol{x}^{\mathbf{n}}\right)\right) \\ \vdots & \ddots, & \vdots \\ \operatorname{cor}\left(Y\left(\boldsymbol{x}^{n}\right), Y\left(\boldsymbol{x}^{\mathbf{1}}\right)\right), & \ldots, & \operatorname{cor}\left(Y\left(\boldsymbol{x}^{n}\right), Y\left(\boldsymbol{x}^{\mathbf{n}}\right)\right) \end{array}\right) \end{aligned} \end{equation} \] 则Y的条件概率为 \[ \begin{equation} L\left(\boldsymbol{Y}^{1}, \boldsymbol{Y}^{2}, \ldots, \boldsymbol{Y}^{n} \mid \mu, \sigma\right)=\frac{1}{\left(2 \pi \sigma^{2}\right)^{n / 2}} \exp \left(-\frac{\Sigma\left(\boldsymbol{Y}^{i}-\boldsymbol{\mu}\right)^{2}}{2 \sigma^{2}}\right) \end{equation} \] 这个条件概率可以表示为 \[ \begin{equation} L=\frac{1}{\left(2 \pi \sigma^{2}\right)^{n / 2}|C|^{1 / 2}} \exp \left[-\frac{(\boldsymbol{y}-\mathbf{1} \mu)^{T} C^{-1}(\boldsymbol{y}-\mathbf{1} \mu)}{2 \sigma^{2}}\right] \end{equation} \] 利用最大似然概率的方法可以得到先验参数\(\hat{\mu},\hat{\sigma},\theta_{i}\)的值,最后通过代入已知和未知点,最大化对数似然概率函数可得式(9.1)。证明过程详见参考文献[8]。
5.2 改进的EGO算法
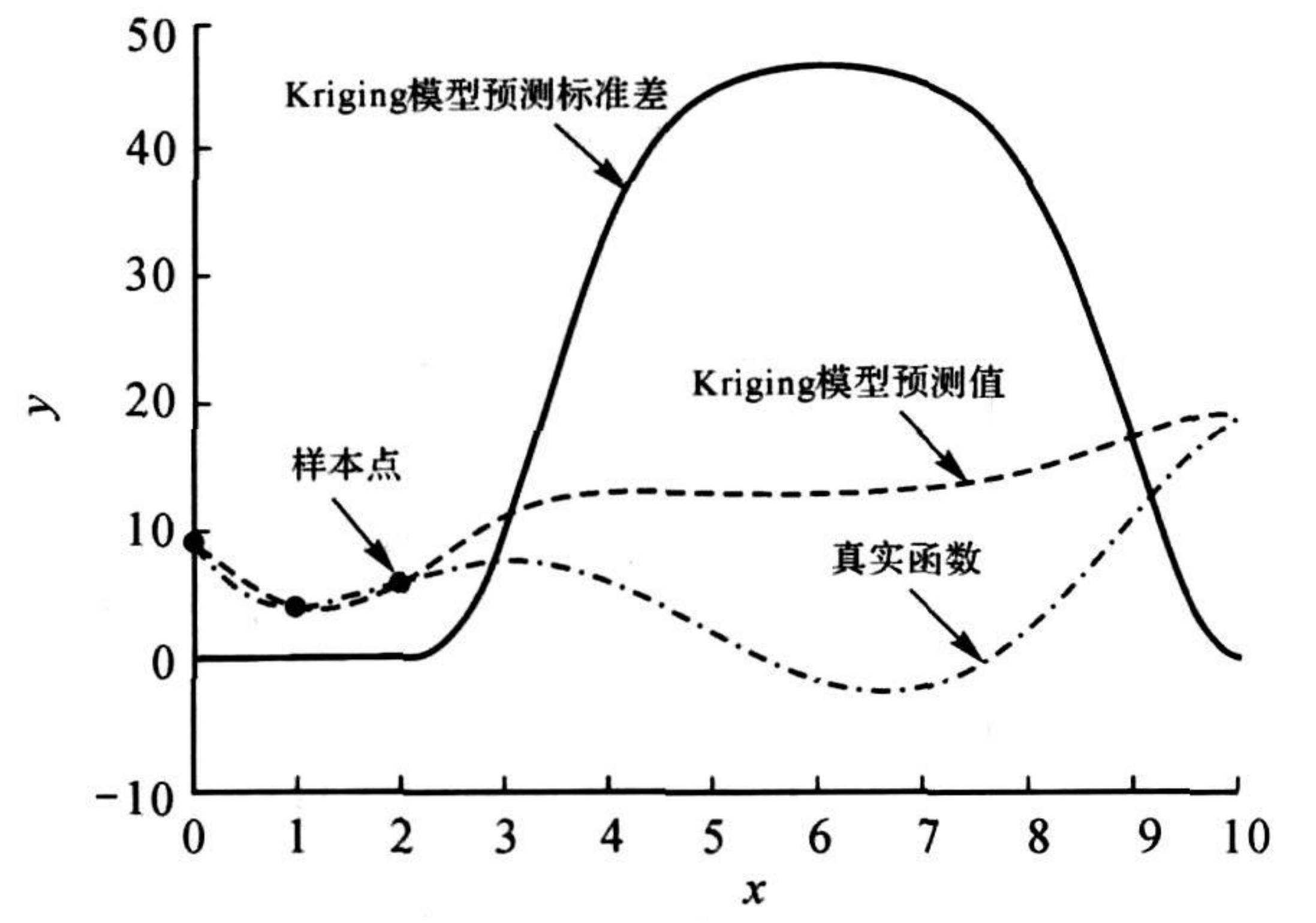
选择代理模型预测值的最优点作为校正点的方法称为响应最优策略。如图所示,当最初的样本点分布不均匀时,Kriging模型的预测值在样本点稀疏的地方与真实函数值相差很大,如果以预测值的最优点作为校正点只是使校正后的Kriging模型在样本点集中的区域预测精度不断提高,在样本点稀疏区域预测精度却没有太多变化,如果真实函数的最优值在样本点稀疏区域,则采用最优策略选择校正点就使得优化过程陷入了局部极值点,可见为了避免采用响应最优策略确定校正点所带来的局部收敛问题,有必要在选择校正点时综合考虑Kriging模型的预测值与预测标准差。
Jones 和 Schonlau提出的EGO算法是一种贝叶斯全局优化算法,针对式(10)表示的一般形式的优化问题,其基本流程为:
- 在设计空间中,利用试验设计方法(DOE)生成初始样本库。
- 采用Kriging模型分别构建设计变量与目标函数、约束函数间的近似映射关系。
- EI (expected improvement)函数的值为目标函数,选择使其最大的点作为校正点。
- 对校正点采用高精度初始模型评估得到校正点的响应值,把校正点及其响应值加入样本库中。
- 重复步骤(2),(3),(4)直至收敛。
其中EI函数(加点准则)定义为: \[ \begin{equation} EI(\boldsymbol{x})=\left(y_{\min }-\mu_{\hat{y}}(\boldsymbol{x})\right) \Phi\left(\frac{y_{\min }-\mu_{\hat{y}}(\boldsymbol{x})}{s_{\hat{y}}(\boldsymbol{x})}\right)+s_{\hat{y}}(\boldsymbol{x}) \phi\left(\frac{y_{\min }-\mu_{\hat{y}}(\boldsymbol{x})}{s_{\hat{y}}(\boldsymbol{x})}\right) \end{equation} \] 其中$y_{} \(为当前试验点上的目标函数的最小值,\){}()\(和\)s{}\(分别是\)\(处的Kriging模型的预测值和标准差,\)( )\(和\)( )$分别是标准正态分布的密度函数和分布函数。
EGO算法将EI准则的最大值点作为新增试验点,故EGO算法倾向于在Kriging模型预测值优(小)和预测不确定性大(预测标准差大)的地方添加新试验点,兼具了开发局部最优区域和探索潜在最优区域的功能。
EI加点准则巧妙利用了Kriging模型的预测不确定性度量能力,倾向于在Kriging模型预测值优和不确定性大的地方添加新试验点,保证了EGO算法的收敛效率和全局收敛性。此后的代理优化算法,大多沿袭了EGO算法的自适应优化思想,并致力于设计出合理的兼具局部开发和全局探索功能的加点准则。
6. 多精度代理模型
代理模型的预测精度取决于其训练集的精度,可以想象训练集的精度越高、数量越多,训练得到的代理模型精度也会越高。但是在实际应用过程中,如果要获取大量高精度训练集需要耗费过多的时间和计算资源,因此为了解决这一问题,我们可以考虑使用多精度代理模型(multi-fidelity surrogate model)。多精度代理模型的出发点是希望能够用大量低精度的数据和少量高精度的数据构建高精度代理模型,这样就可以大大江都获取高精度代理模型的难度。
Reference
[1]王红涛,竺晓程,杜朝辉.基于Kriging代理模型的改进EGO算法研究[J].工程设计学报,2009,16(04):266-270+302.
[2]张建侠. 基于Kriging模型的全局代理优化算法研究[D].南京理工大学,2018.
[3]乐春宇,马义中,张建侠.结合Kriging和物理规划的多目标代理优化算法[J].计算机工程与应用,2019,55(21):240-246.
[4]乐春宇. 基于Kriging模型的代理优化理论研究和应用[D].南京理工大学,2020.
[5] 偷天换日,斗转星移——代理优化算法 https://zhuanlan.zhihu.com/p/99609634
[6] Zhan, D., et al. (2017). "Expected Improvement Matrix-Based Infill Criteria for Expensive Multiobjective Optimization." IEEE Transactions on Evolutionary Computation 21(6): 956-975.
[7] Sacks, Jerome, et al. "Design and analysis of computer experiments."Statistical science(1989): 409-423.
[8] 克里金(Kriging)模型详细推导 - 知乎 (zhihu.com)
[9] Multi-fidelity optimization via surrogate modelling by Alexander I. J. Forrester, Andras Sobester and Andy J. Keane
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!