小波散射网络
本文最后更新于:2021年11月5日 下午
小波散射网络和小波神经网络
1. 小波网络
小波神经网络是一种改进的BP网络,区别是将原来隐藏层的激活函数替换为小波函数,该网络属于小波分析和神经网络“紧致型”结合的一种方式,按照文献[1]中的说法,由于小波变换的时频局部特性,使得该网络在信号处理方面具有自适应性、容错能力和较强的网络逼近能力。小波神经网络的结构
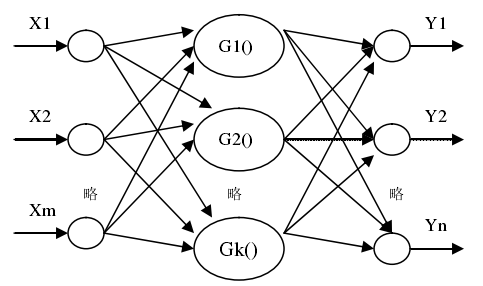
小波网络模型可以表示为 \[ y_{i}(t)=\sum_{i=0}^{n} w_{i j} \psi_{a, b}\left(\sum_{k=0}^{m} w_{j k} x_{k}(t)\right) \] 本质上该网络的表示能力和BP网络并无区别,虽然在某些情况下可以获得更为优良的收敛速度和容错能力,但随着数据量提高,其预设的小波基会限制泛化性能。
讨论:
传统方法里,平移不变表示可以用配准算法或傅立叶变换模量来构造。为了避免傅立叶变换的不稳定性,建议用局部波形(如小波)代替正弦波。然而,小波变换对变化会有些敏感。从小波系数建立不变表示需要引入非线性算子,而卷积网络结构正好可以与之互补,有能力建立对变形反应稳定的大规模不变量。(PS:卷积网络的平移不变性仍然存疑[3])。
2. 小波散射网络
小波散射网络是由Mallat[2]等人提出的具有平移不变性的小波散射卷积神经网络,且对形变稳定,能保留高频信息进行分类。它将具有非线性模量和平均算子的小波反式卷积级联。第一网络层起到SIFT方法的效果,而下一层提供互补的不变信息,改进分类。小波散射网络的数学分析解释了深度卷积网络分类的重要性质。平稳过程的散射表示包含了高阶矩,因此可以区分具有相同傅立叶功率谱的纹理。
设旋转变量$ rG= { angles=2k/K|0≤k<K }\(,\)j$表示尺度且\(0≤j≤J\),则二维方向小波函数为 \[ \psi_{\lambda}(u)=2^{-2 j} \psi\left(2^{-j} r^{-1} u\right), \lambda=2^{-j} r \] 其中如果小波基的傅里叶变换\(\hat{\psi}(\omega)\)的中心频率为\(\eta\),则\(\hat{\psi}_{2^{-j} r}(\omega)=\hat{\psi}\left(2^{j} r^{-1} \omega\right)\)的中心为\(2^{-j}r\eta\),带宽正比于\(2^{-j}\)。
设\(x\)的小波系数为 \[ U[\lambda] x=\left|x * \psi_{\lambda}\right| \] 则序列\(p=(\lambda_{1},\lambda_{2}...\lambda_{m})\)定义了一个路径,沿此路径频率降低,传播算子为 \[ \begin{aligned} U[p] x &=U\left[\lambda_{m}\right] \cdots U\left[\lambda_{2}\right] U\left[\lambda_{1}\right] x \\ &=\left|\| x * \psi_{\lambda_{1}}\right| * \psi_{\lambda_{2}}|\cdots| * \psi_{\lambda_{m}} \end{aligned} \] 由此可得加窗的小波散射系数的表达式: \[ S[p] x(u)=U[p] x * \phi_{2^{J}}(u)=\int U[p] x(v) \phi_{2^{J}}(u-v) d v \] 对于每个路径\(p\),\(S[p] x(u)\)取决于窗的位置\(u\)。平均滤波器\(\phi_{2^{J}}(u)\)使得当\(|c| \ll 2^{J}\)时,\(x_{c}(u)=x(u-c)\) ,因此加窗的小波散射系数是近似具有平移不变性的。
小波散射网络的迭代过程可以表示为如下所示
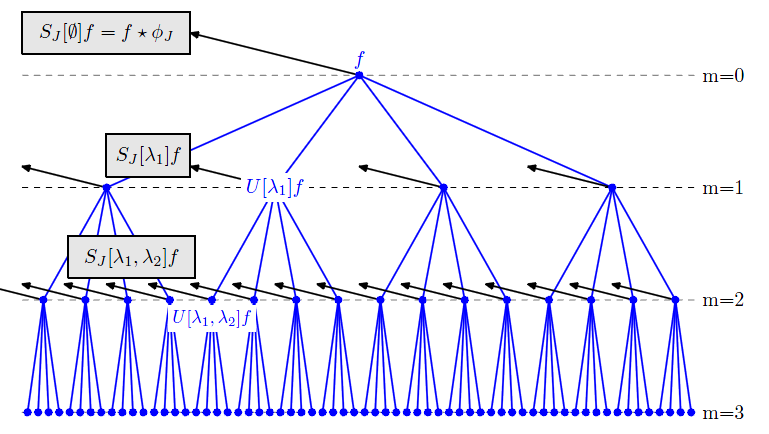
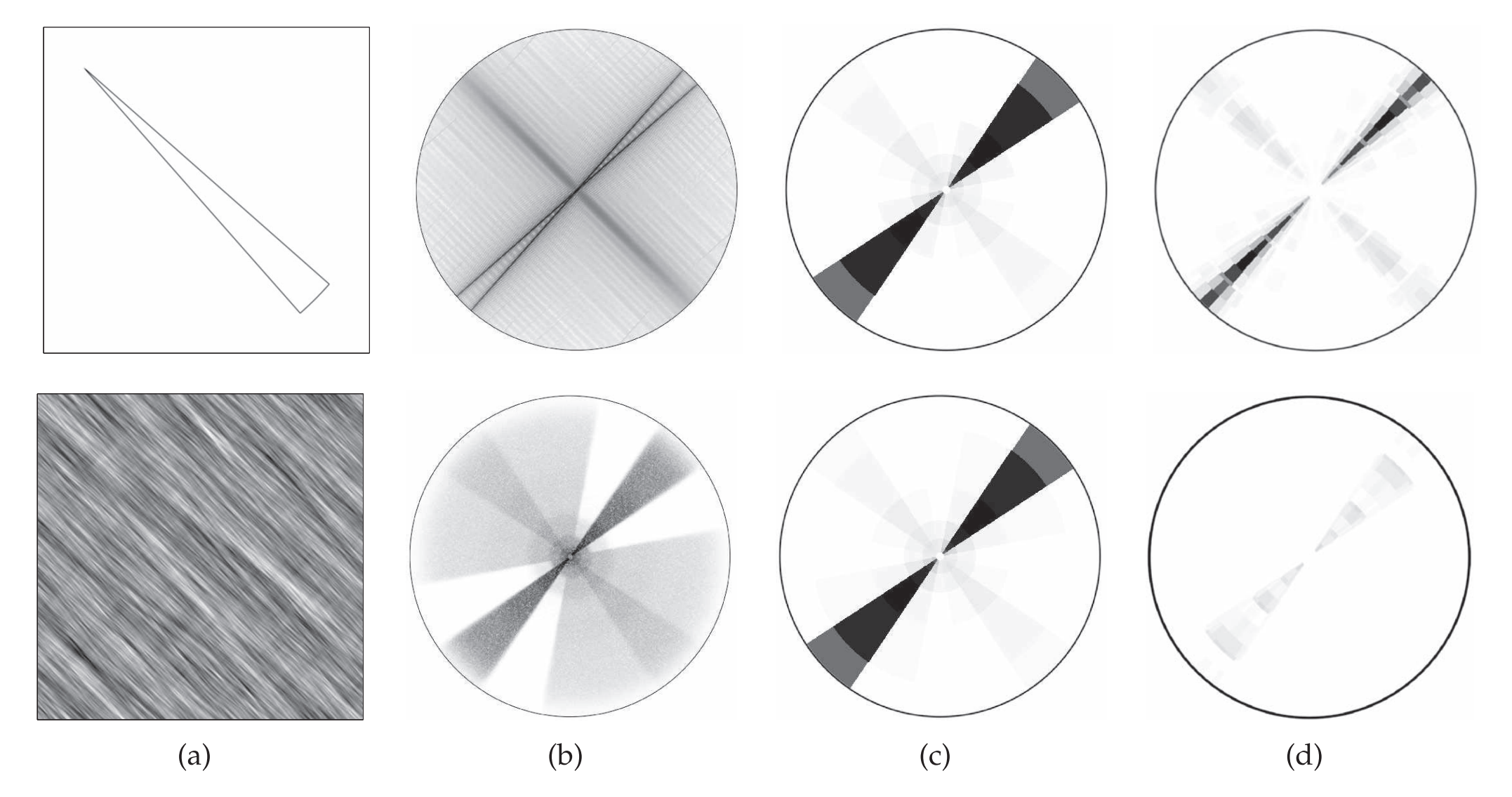
图3为两幅图像的傅里叶变换及其散射系数的幅值。平均尺度系数\(2^J\)等于图像尺寸。上面和下面的图像是非常不同的,但它们有相同的一阶散射系数。二阶系数可以清楚地分辨出这些图像。由于图像小波系数更稀疏,顶部图像的二阶散射系数振幅较大。高阶系数没有显示出来,因为它们的能量可以忽略不计。
参考文献
[1] 左东广, 周帅, 张欣豫. 小波神经网络[J]. 四川兵工学报, 2012(05):90-92+104.
[2] Bruna J, Mallat S. Invariant scattering convolution networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2013, 35(8): 1872-1886.
[3] Azulay A, Weiss Y. Why do deep convolutional networks generalize so poorly to small image transformations?[J]. arXiv preprint arXiv:1805.12177, 2018.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!